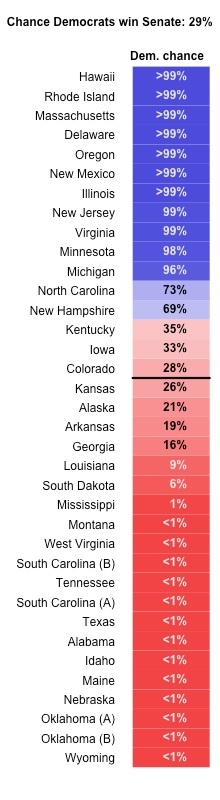
One of the main problems with running a model, especially one that’s polls-only, is that your final result is only as good as the polls that you feed into it. You can do everything right in terms of averaging out the polls and running simulations, and still get tripped up because the polls themselves weren’t getting a representative-enough sample of the population, or were making incorrect assumptions about who’s in the pool of likely voters. The general idea behind poll aggregation is that if you get enough polls, you can smooth out each individual poll’s particular errors and more accurately describe what’s really happening. What happens, though, when every poll in a particular state is suspect?
We try to be skeptical of every poll, but there are some states that especially set our antennae twitching. States that are heavily white, and stagnant in terms of population growth, tend to be easier to poll correctly than states with significant non-white or non-English-speaking populations, or states where there are a lot of people moving in or out. One of the states that falls in the latter category is Colorado, which has a substantial Hispanic minority and also has a lot of population churn as it rapidly grows; it’s also been the site of an effective Democratic ground game in recent elections.
In the Colorado Senate race, we’ve seen Republican challenger Cory Gardner putting up a small but consistent lead in polls for the last month. Part of the reason we’re skeptical of that is because recent history hasn’t really borne that out. In 2010’s Senate race, the majority of polls put Republican Ken Buck in the lead (he lost narrowly to Michael Bennet), while in the 2012 presidential race, a number of polls put Mitt Romney in the lead, even though Barack Obama went on to win the state by more than 5 points. The most notorious example was a Quinnipiac poll that put Romney up by 5, but on the whole, 2012 polling in Colorado had a noticeably higher average error than polling in other swing states.
And now we’ve had several developments in the last few days that further call the reliability of Colorado polling into question. One was that SurveyUSA, one of the more reliable pollsters and also one that works to incorporate new technologies, issued two different polls of Colorado from the same timeframe, one on behalf of the Denver Post and the other on behalf of High Point University. What’s most interesting about this is that the two polls used different methods; both were a mix of robo-dialers and online contacts, but the Post poll used random digit dialing and the High Point poll used registration-based sampling (which relies on voter files).
Registration-based sampling is often considered a better approach, since it lets you zoom in on people likelier to vote instead of casting a very broad net. However, the random digit poll captured a larger, and seemingly more accurate Hispanic population; it had a 16 percent Hispanic component (in line with the 2012 exit polls, where Latinos were 14 percent of the sample), while the RBS poll only was 6 percent Hispanic.
We’ll continue picking apart these polls, and look at changes in the model, over the fold: